This page provides an overview of what you can do with the OpenShift integration. The documentation pages only for a limited number of integrations contain the setup steps and instructions. If you do not see the setup steps here, navigate to the Operations for Applications GUI. The detailed instructions for setting up and configuring all integrations, including the OpenShift integration are on the Setup tab of the integration.
- Log in to your Operations for Applications instance.
- Click Integrations on the toolbar, search for and click the OpenShift tile.
- Click the Setup tab and you will see the most recent and up-to-date instructions.
Kubernetes Integration
Operations for Applications provides a comprehensive solution for monitoring Kubernetes. This integration uses the Observability for Kubernetes Operator to collect detailed metrics from Kubernetes clusters.
Collection
The Observability for Kubernetes Operator makes it easy for you to monitor and manage your Kubernetes environment:
- Collects real-time metrics from all layers of a Kubernetes environment (clusters, nodes, pods, containers and the Kubernetes control plane).
- Supports plugins such as Prometheus, Telegraf and Systemd enabling you to collect metrics from various workloads.
- Auto discovery of pods and services based on annotation and configuration.
- Daemonset mode for high scalability with leader election for monitoring cluster-level resources.
- Rich filtering support.
- Auto reload of configuration changes.
- Internal metrics for tracking the collector health and source of your Kubernetes metrics.
Dashboards
In addition to setting up the metrics flow, this integration also installs dashboards:
- Kubernetes Status: Detailed health of your Kubernetes integration.
- Kubernetes Workloads Troubleshooting: Internal stats of the Kubernetes workloads.
- Kubernetes Summary: Detailed health of your infrastructure and workloads.
- Kubernetes Clusters: Detailed health of your clusters and its nodes, namespaces, pods and containers.
- Kubernetes Nodes: Detailed health of your nodes.
- Kubernetes Pods: Detailed health of your pods broken down by node and namespace.
- Kubernetes Containers: Detailed health of your containers broken down by namespace, node and pod.
- Kubernetes Namespaces: Details of your pods/containers broken down by namespace.
- Kubernetes Metrics Collector Troubleshooting: Internal stats of the Kubernetes Metrics Collector.
- Kubernetes Control Plane: Details of your Kubernetes control plane components.
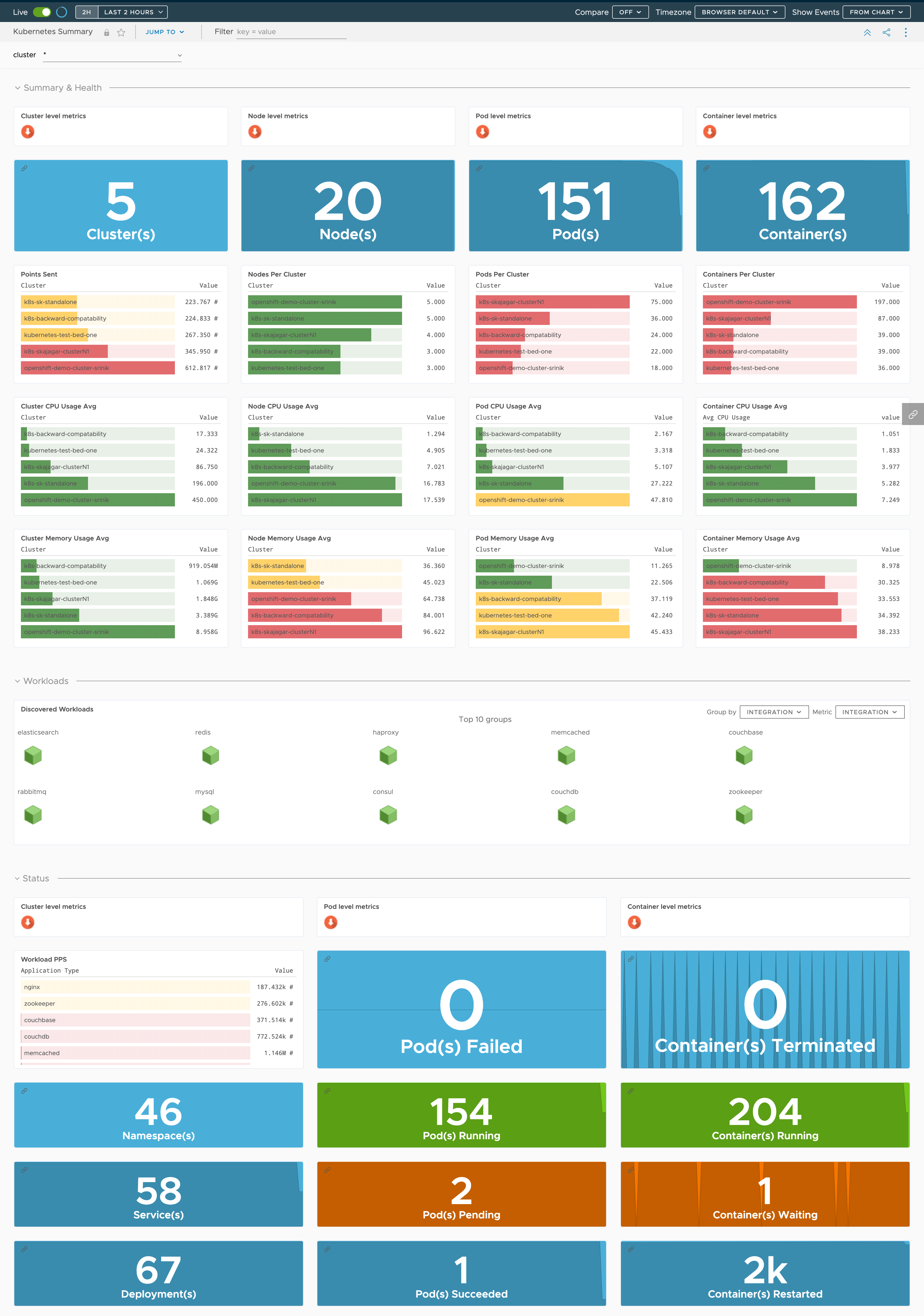
Here’s a preview of the Kubernetes Summary dashboard:
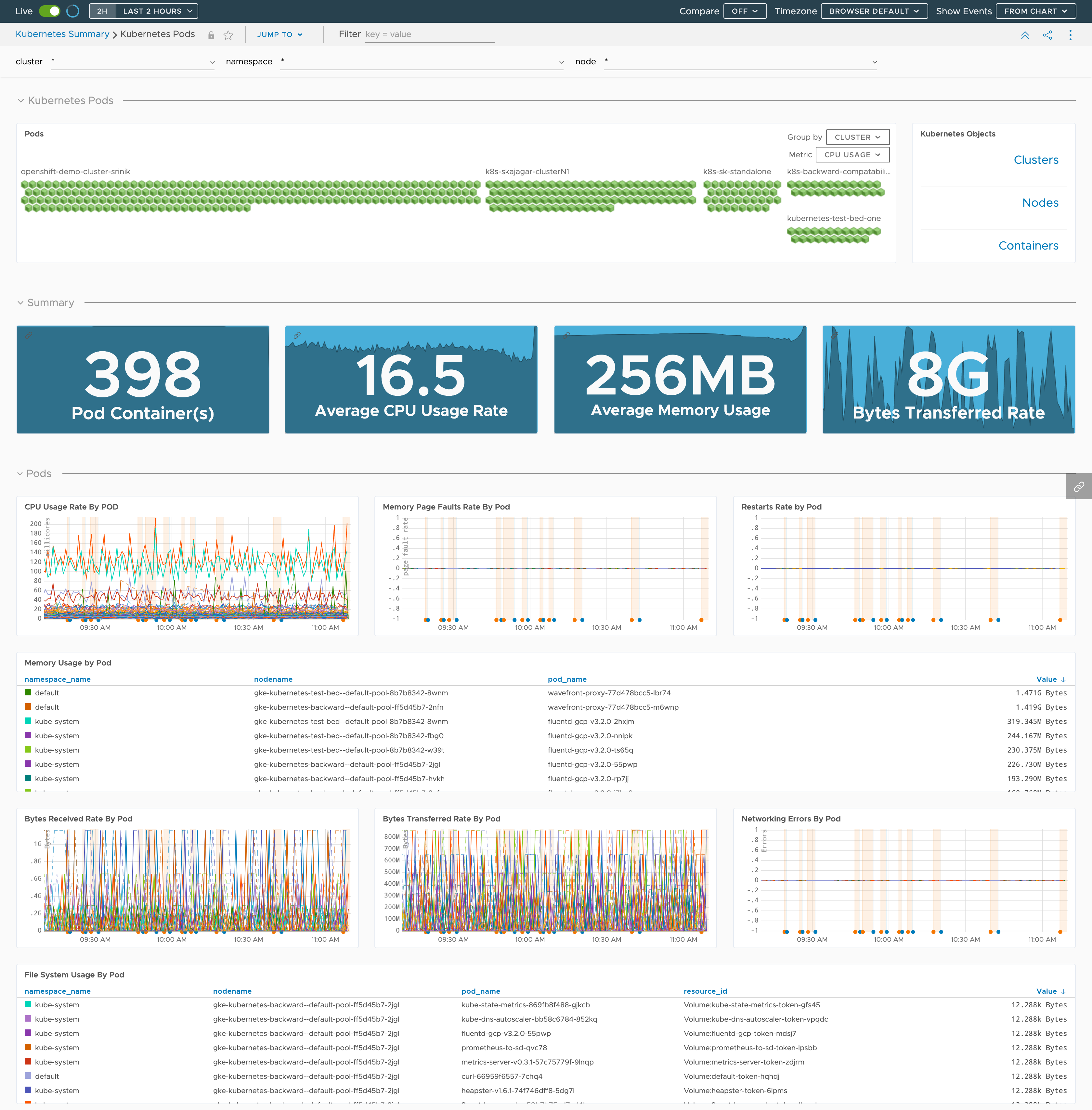
Here’s a preview of the Kubernetes Pods dashboard:
Alerts
The Kubernetes integration contains number of predefined alert templates.
The latest alert templates (in Beta) which can help you monitor Kubernetes workload failures can be found in our alerts documentation.
Kubernetes Clusters Integrations
Operations for Applications uses the Observability for Kubernetes Operator to monitor your Kubernetes clusters. Note: Tanzu Mission Control users follow the steps given in the Tanzu Mission Control documentation.
Add a Kubernetes Integration
VMware Aria Operations for Applications (formerly known as Tanzu Observability by Wavefront) provides a comprehensive solution for monitoring Kubernetes. To set up the Kubernetes integration, you must install and configure our Kubernetes Metrics Collector and a Wavefront proxy. With the 2022-48.x release we introduced the Kubernetes Observability Operator which simplifies the deployment of the Kubernetes Metrics Collector and the Wavefront proxy.
The setup process varies based on the distribution type that you choose to monitor.
- Log in to your product cluster.
- Click Integrations on the toolbar.
- In the Featured section, click the Kubernetes tile.
- Click Add Integration.
Kubernetes Quick Install Using the Kubernetes Operator
- In the Collector Configuration section, configure the deployment options for the cluster.
- In the Cluster Name text box provide the name of your Kubernetes cluster.
- Choose the Kubernetes Cluster as a distribution type.
- Choose whether you want to see the logs for your cluster. By default, the Logs option is enabled.
- Choose whether you want to enable or disable Metrics. By default, the Metrics option is enabled.
- Choose whether you want to use an HTTP Proxy.
If you enable HTTP proxy, to allow outbound traffic, you must add these URLs to your proxy rules:
- Logs:
https://data.mgmt.cloud.vmware.com - Metrics:
https://your_cluster.wavefront.com/
In addition, you must also configure the HTTP proxy settings, such as:
- Host Name - HTTP proxy host name.
- Port - HTTP proxy port number.
- HTTP Proxy Authentication - Can be either basic (with user name and password), or CA certificate - based (with a CA certificate).
- Logs:
-
Enter the authentication options and click Next. You can authenticate to the Operations for Applications REST API using either a user account, or a service account. In both cases, the account must have an Operations for Applications API token associated with it.
- In the Script section, review the script and click the Copy to clipboard button.
- Run the script in your Kubernetes cluster.
- After successful installation, return back to the Operations for Applications UI, and click Finish.
Kubernetes Install in an OpenShift Cluster
Complete the steps below and click Finish.
Note: The Logs feature is not supported when you use OpenShift.
Install and Configure the Operations for Applications Helm Chart on OpenShift Enterprise 4.x
This section contains the installation and configuration steps for full-stack monitoring of OpenShift clusters using the Operations for Applications Helm Chart.
Install the Operations for Applications Helm Chart
-
Log in to the OpenShift Container Platform web console as an administrator.
-
Create a project named
MyProject. -
In the left pane, navigate to Helm and select Install a Helm Chart from the developer catalog.
-
Search for MyProject and click Install Helm Chart.
-
Install from the form view tab. Replace the following parameters with your values:
- clusterName: <OPENSHIFT_CLUSTER_NAME>
- token: <YOUR_WF_API_TOKEN>
- url: https://<YOUR_WF_INSTANCE>.wavefront.com
-
Click Install.
Because default parameters are used, the Kubernetes Metrics Collector runs as a DaemonSet and uses a Wavefront proxy as a sink. The Collector auto discovers the pods and services that expose metrics and dynamically starts collecting metrics for the targets. It collects metrics from the Kubernetes API server, if configured.
Now, go back to your Operations for Applications cluster and search for the
OPENSHIFT_CLUSTER_NAMEin the Kubernetes integration dashboards.
Configure the Collector to Use an Existing Proxy
To configure the Kubernetes Metrics Collector to use a Wavefront proxy that’s already running in your environment, follow these steps:
-
In the OpenShift Container Platform web console, on the yaml view tab, in the proxy section, set enabled to false:
proxy: enabled: false -
On the yaml view tab, add proxyAddress under collector.
collector: proxyAddress: <YOUR_WF_PROXY_ADDRESS>:2878 -
Click Install.
Advanced Wavefront Proxy Configuration
You can configure the proxy to change how it processes your data, port numbers, metric prefix, etc.
Configure the Wavefront Proxy Preprocessor Rules
Preprocessor rules allow you to manipulate incoming metrics before they reach the proxy. For example, you can remove confidential text strings or replace unacceptable characters. Follow these steps to create a ConfigMap with custom preprocessor rules:
-
In the left pane, navigate to Helm, and choose your installation.
-
Under Actions, click Upgrade.
- On the yaml view tab, under proxy, add preprocessor.
proxy: preprocessor: rules.yaml: | '2878': # fix %2F to be a / instead. May be required on EKS. - rule : fix-forward-slash action : replaceRegex scope : pointLine search : "%2F" replace : "/" # replace bad characters ("&", "$", "!", "@") with underscores in the entire point line string - rule : replace-badchars action : replaceRegex scope : pointLine search : "[&\\$!@]" replace : "_" - Click Upgrade.
Install and Configure the Collector on OpenShift Enterprise 3.x
Note: The Helm or manually installed Kubernetes Metrics Collector and Wavefront proxy is deprecated and has reached EOL. Our Observability for Kubernetes Operator replaces the Helm or manually installed Kubernetes Metrics Collector and Wavefront proxy for all Kubernetes Distributions except for the OpenShift Container Platform.
Our Collector supports monitoring of OpenShift clusters:
-
To monitor OpenShift Origin 3.9, follow the steps in Installation and Configuration on OpenShift.
-
To monitor OpenShift Enterprise 3.11, follow the steps in Installation and Configuration of the Operator on OpenShift.
Learn More
Metrics
- Kubernetes Source
- Kubernetes State Source
- Prometheus Source
- Systemd Source
- Telegraf Source
- Collector Health
- cAdvisor Metrics
- Control Plane Metrics
This information comes directly from the Observability for Kubernetes Operator GitHub page.
Kubernetes Source
These metrics are collected from the /stats/summary endpoint on each kubelet running on a node.
Metrics collected per resource:
| Resource | Metrics |
|---|---|
| Cluster | CPU, Memory, Pod/Container counts |
| Namespace | CPU, Memory, Pod/Container counts |
| Nodes | CPU, Memory, Network, Filesystem, Storage, Uptime, Pod/Container counts |
| Pods | CPU, Memory, Network, Filesystem, Storage, Uptime, Restarts, Phase |
| Pod_Containers | CPU, Memory, Filesystem, Storage, Accelerator, Uptime, Restarts, Status |
| System_Containers | CPU, Memory, Uptime |
Metrics collected per type:
| Metric Name | Description |
|---|---|
| cpu.limit | CPU hard limit in millicores. |
| cpu.node_capacity | CPU capacity of a node. |
| cpu.node_allocatable | CPU allocatable of a node in millicores. |
| cpu.node_reservation | Share of CPU that is reserved on the node allocatable in millicores. |
| cpu.node_utilization | CPU utilization as a share of node allocatable in millicores. |
| cpu.request | CPU request (the guaranteed amount of resources) in millicores. |
| cpu.usage | Cumulative amount of consumed CPU time on all cores in nanoseconds. |
| cpu.usage_rate | CPU usage on all cores in millicores. |
| cpu.usage_millicores | CPU usage (sum of all cores) averaged over the sample window in millicores. |
| cpu.load | CPU load in milliloads, i.e., runnable threads * 1000. |
| memory.limit | Memory hard limit in bytes. |
| memory.major_page_faults | Number of major page faults. |
| memory.major_page_faults_rate | Number of major page faults per second. |
| memory.node_capacity | Memory capacity of a node. |
| memory.node_allocatable | Memory allocatable of a node. |
| memory.node_reservation | Share of memory that is reserved on the node allocatable. |
| memory.node_utilization | Memory utilization as a share of memory allocatable based on memory.working_set. |
| memory.page_faults | Number of page faults. |
| memory.page_faults_rate | Number of page faults per second. |
| memory.request | Memory request (the guaranteed amount of resources) in bytes. |
| memory.usage | Total memory usage. |
| memory.cache | Cache memory usage. |
| memory.rss | RSS memory usage. |
| memory.working_set | Total working set usage. Working set is the memory being used and not easily dropped by the kernel. |
| network.rx | Cumulative number of bytes received over the network. |
| network.rx_errors | Cumulative number of errors while receiving over the network. |
| network.rx_errors_rate | Number of errors while receiving over the network per second. |
| network.rx_rate | Number of bytes received over the network per second. |
| network.tx | Cumulative number of bytes sent over the network. |
| network.tx_errors | Cumulative number of errors while sending over the network. |
| network.tx_errors_rate | Number of errors while sending over the network. |
| network.tx_rate | Number of bytes sent over the network per second. |
| filesystem.usage | Total number of bytes consumed on a filesystem. |
| filesystem.limit | The total size of filesystem in bytes. |
| filesystem.available | The number of available bytes remaining in a the filesystem. |
| filesystem.inodes | The number of available inodes in a the filesystem. |
| filesystem.inodes_free | The number of free inodes remaining in a the filesystem. |
| ephemeral_storage.limit | Local ephemeral storage hard limit in bytes. |
| ephemeral_storage.request | Local ephemeral storage request (the guaranteed amount of resources) in bytes. |
| ephemeral_storage.usage | Total local ephemeral storage usage. |
| ephemeral_storage.node_capacity | Local ephemeral storage capacity of a node. |
| ephemeral_storage.node_allocatable | Local ephemeral storage allocatable of a node. |
| ephemeral_storage.node_reservation | Share of local ephemeral storage that is reserved on the node allocatable. |
| ephemeral_storage.node_utilization | Local ephemeral utilization as a share of ephemeral storage allocatable. |
| accelerator.memory_total | Memory capacity of an accelerator. |
| accelerator.memory_used | Memory used of an accelerator. |
| accelerator.duty_cycle | Duty cycle of an accelerator. |
| accelerator.request | Number of accelerator devices requested by container. For example, nvidia.com.gpu.request. |
| uptime | Number of milliseconds since the container was started. |
| <cluster, ns, node>.pod.count | Pod counts by cluster, namespaces and nodes. |
| <cluster, ns, node>.pod_container.count | Container counts by cluster, namespaces and nodes. |
Kubernetes State Source
These are cluster level metrics about the state of Kubernetes objects collected by the Collector leader instance.
| Resource | Metric Name | Description |
|---|---|---|
| Deployment | deployment.desired_replicas | Number of desired pods. |
| Deployment | deployment.available_replicas | Total number of available pods (ready for at least minReadySeconds). |
| Deployment | deployment.ready_replicas | Total number of ready pods. |
| Replicaset | replicaset.desired_replicas | Number of desired replicas. |
| Replicaset | replicaset.available_replicas | Number of available replicas (ready for at least minReadySeconds). |
| Replicaset | replicaset.ready_replicas | Number of ready replicas. |
| ReplicationController | replicationcontroller.desired_replicas | Number of desired replicas. |
| ReplicationController | replicationcontroller.available_replicas | Number of available replicas (ready for at least minReadySeconds). |
| ReplicationController | replicationcontroller.ready_replicas | Number of ready replicas. |
| DaemonSet | daemonset.desired_scheduled | Total number of nodes that should be running the daemon pod. |
| DaemonSet | daemonset.current_scheduled | Number of nodes that are running at least 1 daemon pod and are supposed to run the daemon pod. |
| DaemonSet | daemonset.misscheduled | Number of nodes that are running the daemon pod, but are not supposed to run the daemon pod. |
| DaemonSet | daemonset.ready | Number of nodes that should be running the daemon pod and have one or more of the daemon pod running and ready. |
| Statefulset | statefulset.desired_replicas | Number of desired replicas. |
| Statefulset | statefulset.current_replicas | Number of Pods created by the StatefulSet controller from the StatefulSet version indicated by currentRevision. |
| Statefulset | statefulset.ready_replicas | Number of Pods created by the StatefulSet controller that have a Ready Condition. |
| Statefulset | statefulset.updated_replicas | Number of Pods created by the StatefulSet controller from the StatefulSet version indicated by updateRevision. |
| Job | job.active | Number of actively running pods. |
| Job | job.failed | Number of pods which reached phase Failed. |
| Job | job.succeeded | Number of pods which reached phase Succeeded. |
| Job | job.completions | Desired number of successfully finished pods the job should be run with. -1.0 indicates the value was not set. |
| Job | job.parallelism | Maximum desired number of pods the job should run at any given time. -1.0 indicates the value was not set. |
| CronJob | cronjob.active | Number of currently running jobs. |
| HorizontalPodAutoscaler | hpa.desired_replicas | Desired number of replicas of pods managed by this autoscaler as last calculated by the autoscaler. |
| HorizontalPodAutoscaler | hpa.min_replicas | Lower limit for the number of replicas to which the autoscaler can scale down. |
| HorizontalPodAutoscaler | hpa.max_replicas | Upper limit for the number of replicas to which the autoscaler can scale up. |
| HorizontalPodAutoscaler | hpa.current_replicas | Current number of replicas of pods managed by this autoscaler, as last seen by the autoscaler. |
| Node | node.status.condition | Status of all running nodes. |
| Node | node.spec.taint | Node taints (one metric per node taint). |
| Node | node.info | Detailed node information (kernel version, kubelet version etc). |
Prometheus Source
Varies by scrape target.
Systemd Source
These are Linux systemd metrics that can be collected by each Collector instance.
| Metric Name | Description |
|---|---|
| kubernetes.systemd.unit.state | Unit state (active, inactive etc). |
| kubernetes.systemd.unit.start.time.seconds | Start time of the unit since epoch in seconds. |
| kubernetes.systemd.system.running | Whether the system is operational ( systemctl is-system-running ). |
| kubernetes.systemd.units | Top level summary of systemd unit states (# of active, inactive units etc). |
| kubernetes.systemd.service.restart.total | Service unit count of Restart triggers. |
| kubernetes.systemd.timer.last.trigger.seconds | Seconds since epoch of last trigger. |
| kubernetes.systemd.socket.accepted.connections.total | Total number of accepted socket connections. |
| kubernetes.systemd.socket.current.connections | Current number of socket connections. |
| kubernetes.systemd_socket_refused_connections_total | Total number of refused socket connections. |
Telegraf Source
Host metrics:
| Metric Prefix | Metrics Collected |
|---|---|
| mem. | metrics list |
| net. | metrics list |
| netstat. | metrics list |
| linux.sysctl.fs. | metrics list |
| swap. | metrics list |
| cpu. | metrics list |
| disk. | metrics list |
| diskio. | metrics list |
| system. | metrics list |
| kernel. | metrics list |
| processes. | metrics list |
Application metrics:
| Plugin Name | Metrics Collected |
|---|---|
| activemq | metrics list |
| apache | metrics list |
| consul | metrics list |
| couchbase | metrics list |
| couchdb | metrics list |
| haproxy | metrics list |
| jolokia2 | metrics list |
| memcached | metrics list |
| mongodb | metrics list |
| mysql | metrics list |
| nginx | metrics list |
| nginx plus | metrics list |
| postgresql | metrics list |
| rabbitmq | metrics list |
| redis | metrics list |
| riak | metrics list |
| zookeeper | metrics list |
Collector Health Metrics
These are internal metrics about the health and configuration of the Kubernetes Metrics Collector.
| Metric Name | Description |
|---|---|
| kubernetes.collector.discovery.enabled | Whether discovery is enabled. 0 (false) or 1 (true). |
| kubernetes.collector.discovery.rules.count | Number of discovery configuration rules. |
| kubernetes.collector.discovery.targets.registered | Number of auto discovered scrape targets currently being monitored. |
| kubernetes.collector.events.* | Events received, sent, and filtered. |
| kubernetes.collector.leaderelection.error | Leader election error counter. Only emitted in DaemonSet mode. |
| kubernetes.collector.leaderelection.leading | 1 indicates a pod is the leader. 0 indicates a pod is not the leader. Only emitted in DaemonSet mode. |
| kubernetes.collector.runtime.* | Go runtime metrics (MemStats, NumGoroutine, etc). |
| kubernetes.collector.sink.manager.timeouts | Counter of timeouts in sending data to Operations for Applications. |
| kubernetes.collector.source.manager.providers | Number of configured source providers. Includes sources configured via auto-discovery. |
| kubernetes.collector.source.manager.scrape.errors | Scrape error counter across all sources. |
| kubernetes.collector.source.manager.scrape.latency.* | Scrape latencies across all sources. |
| kubernetes.collector.source.manager.scrape.timeouts | Scrape timeout counter across all sources. |
| kubernetes.collector.source.manager.sources | Number of configured scrape targets. For example, a single Kubernetes source provider on a 10 node cluster will yield a count of 10. |
| kubernetes.collector.source.points.collected | Collected points counter per source type. |
| kubernetes.collector.source.points.filtered | Filtered points counter per source type. |
| kubernetes.collector.version | The version of the Kubernetes Metrics Collector. |
| kubernetes.collector.wavefront.points.* | Operations for Applications sink points sent, filtered, errors etc. |
| kubernetes.collector.wavefront.events.* | Operations for Applications sink events sent, filtered, errors etc. |
| kubernetes.collector.wavefront.sender.type | 1 for proxy and 0 for direct ingestion. |
| kubernetes.collector.histograms.duplicates | Number of duplicate histogram series tagged by metric name (not emitted if no duplicates) |
cAdvisor Metrics
cAdvisor exposes a Prometheus endpoint which the collector can consume. See the cAdvisor documentation for details on what metrics are available.
Control Plane Metrics
These are metrics for the health of the Kubernetes Control Plane.
Metrics collected per type:
| Metric Name | Description | K8s environment exceptions |
|---|---|---|
| kubernetes.node.cpu.node_utilization (node_role=”control-plane”) | CPU utilization as a share of the contol-plane node allocatable in millicores. | Not available in AKS, EKS, GKE |
| kubernetes.node.memory.working_set (node_role=”control-plane”) | Total working set usage of the control-plane node. Working set is the memory being used and not easily dropped by the kernel. | Not available in AKS, EKS, GKE |
| kubernetes.node.filesystem.usage (node_role=”control-plane”) | Total number of bytes consumed on a filesystem of the control-plane node. | Not available in AKS, EKS, GKE |
| kubernetes.controlplane.apiserver.storage.objects.gauge | etcd object counts. | Not available from kubernetes release version 1.23 and later |
| kubernetes.controlplane.etcd.db.total.size.in.bytes.gauge | etcd database size. | Kubernetes <= v1.25 |
| kubernetes.controlplane.apiserver.storage.db.total.size.in.bytes.gauge | etcd database size. | Kubernetes >= v1.26 |
| kubernetes.controlplane.apiserver.request.duration.seconds.bucket | Histogram buckets for API server request latency. | - |
| kubernetes.controlplane.apiserver.request.total.counter | API server total request count. | - |
| kubernetes.controlplane.workqueue.adds.total.counter | Current depth of API server work queue. | - |
| kubernetes.controlplane.workqueue.queue.duration.seconds.bucket | Histogram buckets for work queue latency. | - |
| kubernetes.controlplane.coredns.dns.request.duration.seconds.bucket | Histogram buckets for CoreDNS request latency. | Not available in GKE, OpenShift |
| kubernetes.controlplane.coredns.dns.responses.total.counter | CoreDNS total response count. | Not available in GKE, OpenShift |
Alerts
- K8s pod CPU usage too high:Alert reports when the CPU millicore utilization of a pod exceeds the CPU millicore limit defined constantly. Having the CPU going over the set limit will cause the pod to suffer from CPU throttling which is going to affect the pod’s performance. When this happens, please make sure the CPU resource limitation set for the pod is correctly configured.
- K8s pod memory usage too high:Alert reports when the memory utilization of a pod is constantly at high percentage.
- K8s too many pods crashing:Alert reports when a pod’s running and succeeded phase percentage is below the required level specified.
- K8s node CPU usage too high:Alert reports when a node’s cpu utilization percentage is constantly high.
- K8s node storage usage too high:Alert reports when a node’s storage is almost full.
- K8s node memory usage too high:Alert reports when the memory utilization of a node is constantly high.
- K8s too many containers not running:Alert reports when the percentage of containers not running is constantly high.
- K8s node unhealthy:Alert reports when a node’s condition is not ready or status is not true.
- K8s pod storage usage too high:Alerts reports when the pod’s storage is almost full.
- K8s Observability status is unhealthy :The K8s observability status is unhealthy.